[튜토리얼5] 맞춤 학습 - 자세히 살펴보기
이번 튜토리얼은 이전 튜토리얼에서 학습한 기본 모델 생성을 발전시켜 다음의 3가지 단계를 통해 붓꽃의 품종을 분류하기 위한 머신러닝 모델을 구축할 것입니다.
- 모델 구축
- 모델 학습
- 모델을 사용한 예측
import warnings
warnings.filterwarnings(action='ignore')
import tensorflow as tf
import os
import matplotlib.pyplot as plt
import numpy as np
목차
- 붓꽃 분류 문제
- 학습 데이터 가저오기 및 파싱
- 2.1 데이터셋 다운로드
- 2.2 데이터 탐색
- 2.3 tf.data.Dataset 생성
- 모델 타입 선정
- 3.1 왜 모델을 사용해야하는가?
- 3.2 모델 선정
- 3.3 케라스를 사용한 모델 생성
- 3.4 모델 사용
- 모델 학습하기
- 4.1 손실 함수와 그래디언트 함수 정의하기
- 4.2 옵티마이저 생성
- 4.3 학습 루프
- 4.4 시간에 따른 손실함수 시각화
- 모델 유효성 평가
- 5.1 테스트 데이터 세트 설정
- 5.2 테스트 데이터 세트를 사용한 모델 평가
- 학습된 모델로 예측하기
1. 붓꽃 분류 문제
먼저 당신이 식물학자라고 생각하고, 주어진 붓꽃을 자동적으로 분류하는 방법을 찾고 있다고 가정합시다. 머신러닝은 통계적으로 꽃을 분류할 수 있는 다양한 알고리즘을 제공합니다. 특히 정교한 머신러닝 프로그램은 사진을 통해 꽃을 분류할 수도 있습니다. 이번 튜토리얼의 목적은 그것보다는 좀 더 간단하게, 측정된 꽃받침과 꽃잎의 길이와 폭을 토대로 붓꽃을 분류하는 것입니다.
이 붓꽃은 약 300종입니다. 하지만 이번 튜토리얼에서는 오직 다음의 3가지 품종을 기준으로 분류할 것입니다.
- Iris setosa
- Iris virginica
- Iris versicolor

|
|
그림 1. Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor, (by Dlanglois, CC BY-SA 3.0), and Iris virginica (by Frank Mayfield, CC BY-SA 2.0). |
다행히도 다른 사람들이 먼저 꽃받침과 꽃잎의 길이와 폭이 측정된 120개의 붓꽃 데이터를 만들어 놓았습니다. 이것은 머신러닝 분류 문제에 있어 초보자에게 가장 유명한 고전 데이터셋입니다.
2. 학습 데이터 가져오기 및 파싱
붓꽃 데이터를 불러오고 파이썬 프로그램이 사용할 수 있는 구조로 전환합니다.
2.1 데이터셋 다운로드
tf.keras.utils.get_file 함수를 사용하여 데이터셋을 다운로드합니다. 이 함수는 다운로드된 파일의 경로를 반환합니다.
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("데이터셋이 복사된 위치: {}".format(train_dataset_fp))
2.2 데이터 탐색
이 데이터셋(iris_training.csv)은 콤마(‘,’)로 구분된 CSV(comma-separated values) 파일입니다. head -n5 명령을 사용하여 처음 5개 항목을 확인합니다.
!head -n5 {train_dataset_fp}
처음 5개의 데이터로부터 다음을 주목하세요.
- 첫 번째 줄은 다음과 같은 정보를 포함하고 있는 헤더(header) 입니다.
- 총 120개의 샘플이 있으며, 각 샘플들은 4개의 피쳐(feature), 3개의 레이블(label)을 가지고 있음을 확인할 수 있습니다.
- 후속행은 데이터 레코드입니다. 한 줄당 한 개의 샘플을 나타냅니다.
- 처음 4개의 필드는 특성(피쳐) 입니다 : 이것들은 샘플의 특징을 나타냅니다. 이 필드들은 붓꽃의 측정값을 float형으로 나타냅니다.
- 마지막 컬럼(column)은 레이블(label) 입니다 : 레이블은 예측하고자 하는 값을 나타냅니다. 이 데이터셋에서는 꽃의 이름과 관련된 정수값인 0, 1, 2를 나타냅니다.
이를 코드로 표현하면 다음과 같습니다.:
# CSV 파일안에서 컬럼의 순서
# 꽃받침 길이, 꽃받침 폭, 꽃잎 길이, 꽃잎 폭, 꽃 이름(품종)
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("피쳐: {}".format(feature_names))
print("레이블: {}".format(label_name))
각각의 레이블은 “setosa”와 같은 문자형 이름과 연관되어있습니다. 하지만 머신러닝은 전형적으로 숫자형 값에 의존합니다. 따라서 각 레이블이 어떤 품종을 나타내는지 확인하기 위해 다음과 같이 매핑(mapping) 합니다.
0: Iris setosa1: Iris versicolor2: Iris virginica
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
2.3 tf.data.Dataset 생성
텐서플로우의 데이터셋 API는 데이터를 적재할 때 발생하는 다양한 경우를 다룰 수 있습니다. 이는 학습에 필요한 형태로 데이터를 읽고 변환하는 고수준 API입니다.
데이터셋이 CSV 파일 형태이므로, make_csv_dataset 함수를 사용하겠습니다. 이 함수는 학습 모델을 위한 데이터를 생성하므로, 초기값은 셔플(shuffle=True, shuffle_buffer_size=10000)과 무한 반복(num_epochs=None)으로 설정되어있으며, 배치 사이즈(batch_size)를 32로 설정해주었습니다.
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
- 코드 실행 시 발생하는 위와 같은 WARNING은 tf.data 내에서
parallel_interleave를 사용하여 발생하는 경고 메시지입니다. 텐서플로우 2.0 version에서는 parallel_interleave을 더 이상 사용하지 않기 때문에 발생합니다.참고 링크
make_csv_dataset 함수는 (features, label) 쌍으로 구성된 tf.data.Dataset을 반환합니다. features는 딕셔너리 객체인: {'feature_name': value}로 주어집니다. 데이터셋 내에 있는 피쳐(feature)을 살펴봅시다.
features, labels = next(iter(train_dataset))
print(features)
유사한 피쳐의 값은 다음과 같이 군집화 되어있다는 사실에 주목하세요. 각 샘플 행의 필드는 해당 피쳐 배열에 추가됩니다. batch_size를 조절하여 이 피쳐 배열에 저장된 샘플의 수를 설정하세요.
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
모델 구축 단계를 단순화하기 위해, 피쳐 딕셔너리를 (batch_size, num_features)의 형태를 가지는 단일 배열로 다시 구성하는 함수를 생성합니다.
이 함수는 텐서의 리스트(list)로부터 값을 취하고 특정한 차원으로 결합된 텐서를 생성하는 tf.stack 메서드(method)를 사용합니다.
def pack_features_vector(features, labels):
"""피쳐들을 단일 배열로 묶습니다."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
그 후 각 (features,label)쌍의 피쳐를 학습 데이터셋에 쌓기 위해 tf.data.Dataset.map 메서드를 사용합니다.
train_dataset = train_dataset.map(pack_features_vector)
데이터셋의 피쳐 요소는 이제 형태가 (batch_size, num_features)인 배열입니다. 첫 5개행의 샘플을 살펴봅시다.
features, labels = next(iter(train_dataset))
print(features[:5])
3. 모델 타입 선정
3.1 왜 모델을 사용해야하는가?
모델은 피쳐(feature)들과 레이블(label)사이의 관계를 나타냅니다. 따라서 붓꽃 분류 문제에서 모델은 측정된 꽃받침과 꽃잎 사이의 관계를 정의하고 붓꽃의 품종을 예측합니다. 몇 가지 간단한 모델은 간단한 대수학으로 표현할 수 있으나, 복잡한 머신러닝 모델은 요약하기 힘든 수의 매개변수를 가지고 있습니다.
머신러닝을 사용하지 않으면서 4가지 피쳐 사이의 관계를 결정하고 각 붓꽃의 품종을 예측하실 수 있을까요? 만약 특정 품종의 꽃받침과 꽃잎과의 관계를 정의할 수 있을 정도로 데이터셋을 분석했다면, 전통적인 프로그래밍 기술(예를 들어 굉장히 많은 조건문)을 사용하여 모델을 만들 수 있을까요? 만약 더 복잡한 데이터셋이라면 어떠실 것 같은가요?
3.2 모델 선정
이제 학습을 위해 사용할 모델의 종류를 선정해야합니다. 모델에는 여러 종류가 있고, 이를 선택하는 것은 많은 경험이 필요합니다. 이번 튜토리얼에서는 붓꽃 분류 문제를 해결하기위해 신경망(neural network)모델을 사용하겠습니다. 신경망 모델은 피쳐와 레이블 사이의 복잡한 관계를 찾을 수 있습니다. 신경망은 하나 또는 그 이상의 은닉레이어(hidden layer)으로 구성된 그래프입니다. 각각의 은닉레이어는 하나 이상의 뉴런(neuron)으로 구성되어있습니다. 신경망의 범주에도 몇가지가 있는데, 이번 튜토리얼에서는 밀집(dense) 또는 완전 연결 신경망(fully-connected neural network)를 사용합니다: 완전 연결 신경망(fully-connected neural network)은 하나의 뉴런에 이전레이어의 모든 뉴런의 입력을 받는 신경망입니다. 예를 들어, 그림 2는 입력레이어, 2개의 은닉레이어, 그리고 마지막 출력레이어로 구성된 완전 연결 신경망입니다.
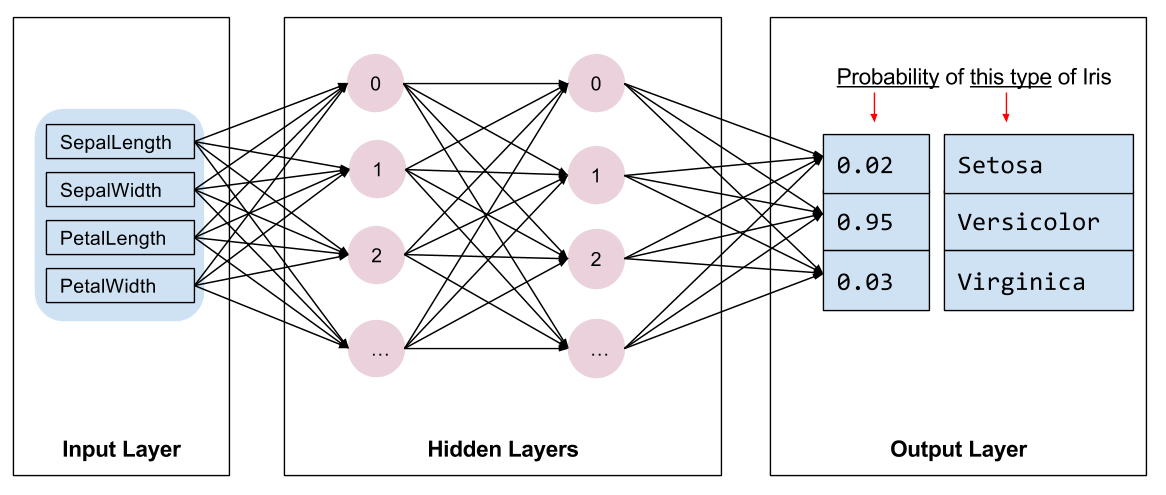
|
|
그림 2. 피쳐, 은닉레이어, 예측으로 구성된 신경망 |
그림 2의 모델이 학습된 다음, 레이블 되어있지 않은 데이터를 제공했을때, 모델은 주어진 데이터의 3가지 품종(주어진 레이블의 개수)에 대한 예측을 출력합니다. 이러한 예측은 추론(inference)이라고 불립니다. 이 샘플에서 예측의 출력의 합은 1.0입니다. 그림 2에서 예측은 Iris setosa 0.02, Iris versicolor 0.95, Iris virginica에 0.03로 주어집니다. 이는 모델이 95%의 확률로 주어진 데이터를 Iris versicolor로 예측한다는 것을 의미합니다.
3.3 케라스를 사용한 모델 생성
텐서플로우의 tf.keras API는 모델과 레이어를 생성하기 위한 풍부한 라이브러리를 제공합니다. 케라스가 구성 요소를 연결하기 위한 복잡함을 모두 처리해 주기 때문에 케라스를 사용하면 모델을 구축하고 실험하는 것이 쉽습니다.
tf.keras.Sequential은 여러 레이어를 연이어 쌓은 모델입니다. 이 구조는 레이어의 객체를 취하며, 아래의 경우 각 레이어당 10개의 노드(node) 혹은 뉴런을 가지는 2개의 완전 연결((Dense) 레이어과 3개(예측 레이블의 수)의 노드 혹은 뉴런을 가지는 출력 레이어로 구성되어있습니다. 첫 번째 레이어의 input_shape 매개변수는 데이터셋의 피쳐의 수와 관계가 있습니다.
tf.nn은 신경망 작업을 위한 래퍼 클래스(wrapper class)로, softmax, relu와 같은 다양한 액티베이션 함수(Activation function)을 사용할 수 있습니다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # 입력의 형태가 필요합니다.
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
활성화 함수(activation function)는 각 레이어에서 출력의 형태를 결정합니다. 이러한 비선형성은 모델에 있어서 중요한 요소이며, 활성화 함수가 없는 모델은 하나의 레이어와 동일하다고 생각할 수 있습니다. 사용 가능한 활성화 함수는 많지만, ReLU 함수가 은닉레이어에 주로 사용됩니다.
이상적인 은닉레이어와 뉴런의 개수는 문제와 데이터셋에 의해 좌우됩니다. 다른 머신러닝의 특징들과 마찬가지로, 최적의 신경망 타입을 결정하는 것은 많은 경험과 지식이 필요합니다. 경험을 토대로 보면 은닉레이어와 뉴런의 증가는 일반적으로 강력한 모델을 생성하기때문에 모델을 효과적으로 학습시키기 위해서는 더 많은 데이터가 필요하다는 것을 알 수 있습니다.
3.4 모델 사용
이 모델이 피쳐의 배치에 대해 수행하는 작업을 간단히 살펴봅시다.
predictions = model(features)
predictions[:5]
각 샘플은 각 클래스에 대한 로짓(logit)을 반환합니다.
이 로짓(logit)을 각 클래스에 대한 확률로 변환하기 위하서 소프트맥스(softmax) 함수를 사용하겠습니다.
tf.nn.softmax(predictions[:5])
tf.argmax는 예측된 값 중 가장 큰 확률(원하는 클래스)을 반환합니다. 하지만 모델이 아직 학습되지 않았으므로 이는 좋은 예측이 아닙니다.
print(" 예측: {}".format(tf.argmax(predictions, axis=1)))
print("레이블: {}".format(labels))
correct_count = np.sum(np.equal(np.array(tf.argmax(predictions, axis=1)),np.array(labels)))
print("예측 정확도: {}%".format(correct_count/len(labels)*100))
4. 모델 학습하기
학습 단계 는 모델이 점진적으로 최적화되거나 데이터셋을 학습하는 머신러닝 과정입니다. 학습의 목적은 미지의 데이터를 예측하기 위해, 학습 데이터셋의 구조에 대해서 충분히 학습하는 것입니다. 만약 모델이 학습 데이터셋에 대해서 과하게 학습된다면 이는 학습 데이터셋에 대해서만 제대로 작동할 것이며, 일반화되기 힘들 것입니다. 이러한 문제를 과대적합(overfitting)이라고 합니다. 이는 마치 문제를 이해하고 해결한다기보다는 답을 기억해서 문제를 푸는 것이라고 생각할 수 있습니다.
붓꽃 분류 문제는 지도 학습(supervised machine learning) 의 예시 중 하나입니다. 지도학습은 모델이 레이블을 포함한 학습 데이터를 학습합니다. 그러나 비지도 학습(unsupervised machine learning)에서는 학습 데이터가 레이블을 포함하고 있지 않기 때문에 피쳐 간의 패턴을 찾습니다.
4.1 손실 함수와 그래디언트 함수 정의하기
학습과 평가단계에서 모델의 손실(loss)을 계산해야 합니다. 손실은 모델의 예측이 원하는 레이블과 얼마나 일치하는지, 또한 모델이 얼마나 잘 작동하는지에 대한 척도로 사용됩니다. 이 값을 최소화하는 것이 목표입니다.
모델의 손실은 tf.keras.losses.categorical_crossentropy 함수를 사용해 계산할 것입니다. 이 함수는 모델의 클래스(레이블)과 예측된 값을 입력받아 샘플의 평균 손실을 반환합니다.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y):
y_ = model(x)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels)
print("손실 테스트: {}".format(l))
모델을 최적화하기 위해 사용되는 그래디언트(gradient)를 계산하기 위해 tf.GradientTape 컨텍스트를 사용합니다.
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
4.2 옵티마이저 생성
옵티마이저(optimizer)는 손실 함수를 최소화하기 위해 계산된 그래디언트를 모델의 변수에 적용합니다. 손실 함수를 구부러진 곡선의 표면(그림 3)으로 생각할 수 있으며, 이 함수의 최저점을 찾고자 합니다. 그래디언트는 가장 가파른 상승 방향을 가리키며 이 방향의 반대 방향으로 이동합니다. 각 배치마다의 손실과 기울기를 반복적으로 계산하여 학습과정 동안 모델을 조정합니다. 점진적으로, 모델은 손실을 최소화하기 위해 가중치(weight)와 편향(bias)의 최적의 조합을 찾아냅니다. 손실이 낮을수록 더 좋은 모델의 예측을 기대할 수 있습니다.

|
|
그림 3. 3차원 공간에 대한 최적화 알고리즘 시각화. (Source: Stanford class CS231n, MIT License, Image credit: Alec Radford) |
텐서플로우는 학습을 위해 사용 가능한 여러종류의 최적화 알고리즘을 가지고 있습니다. 이번 모델에서는 확률적 경사 하강법(stochastic gradient descent, SGD)을 구현한 tf.train.GradientDescentOptimizer를 사용하겠습니다. learning_rate은 경사하강 과정의 크기를 나타내는 매개변수이며, 더 나은 결과를 위해 조절가능한 하이퍼파라미터(hyperparameter) 입니다.
옵티마이저(optimizer)를 설정합니다.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
한 번의 최적화 단계를 계산하기 위해 다음과 같이 사용합니다.
loss_value, grads = grad(model, features, labels)
print("단계: {}, 초기 손실: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("단계: {}, 손실: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels).numpy()))
4.3 학습 루프
모든 사항이 갖춰졌으므로 모델을 학습할 준비가 되었습니다. 학습 루프는 더 좋은 예측을 위해 데이터셋을 모델로 제공합니다. 다음의 코드 블럭은 아래의 학습 단계를 작성한 것입니다.
- 각 에포크(epoch) 반복. 에포크는 데이터셋을 통과시키는 횟수입니다.
- 에포크 내에서, 피쳐 (
x)와 레이블 (y)가 포함된 학습 데이터셋에 있는 샘플을 반복합니다. - 샘플의 피쳐를 사용하여 결과를 예측 하고 레이블과 비교합니다. 예측의 부정확도를 측정하고 모델의 손실과 그래디언트를 계산하기 위해 사용합니다.
- 모델의 변수를 업데이트하기 위해
옵티마이저를 사용합니다. - 시각화를 위해 몇가지 값들을 저장합니다.
- 각 에포크를 반복합니다.
num_epochs 변수는 데이터셋의 반복 횟수입니다. 이 때, 모델을 길게 학습하는 것이 항상 더 나은 모델이 될 것이라고 보장하지는 못합니다. num_epochs는 조정가능한 하이퍼파라미터(hyperparameter)입니다. 적절한 횟수를 선택하는 것은 많은 경험과 직관이 필요합니다.
## 참고: 이 셀을 다시 실행하면 동일한 모델의 변수가 사용됩니다.
print("> 모델 학습을 시작합니다.")
# 도식화를 위해 결과를 저장합니다.
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# 학습 루프 - 32개의 배치를 사용합니다.
for x, y in train_dataset:
# 모델을 최적화합니다.
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 진행 상황을 추적합니다.
epoch_loss_avg(loss_value) # 현재 배치 손실을 추가합니다.
# 예측된 레이블과 실제 레이블 비교합니다.
epoch_accuracy(y, model(x))
# epoch 종료
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("에포크 {:03d}: 손실: {:.3f}, 정확도: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
4.4 시간에 따른 손실함수 시각화
모델의 학습 과정을 출력하는 것도 도움이 되지만, 학습 과정을 직접 보는 것이 더 도움이 되곤합니다. 텐서보드(tensorboard)는 텐서플로에 패키지 되어있는 굉장히 유용한 시각화 툴입니다. 하지만 matplotlib 모듈을 사용하여 일반적인 도표를 출력할 수 있습니다.
이 도표를 해석하는 것은 여러 경험이 필요하지만, 결국 모델을 최적화하기 위해서는 손실 이 내려가고 정확도 가 올라가는 것을 원합니다.
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('training')
axes[0].set_ylabel("loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("accuracy", fontsize=14)
axes[1].set_xlabel("epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
5. 모델 유효성 평가
이제 모델이 학습되었습니다. 학습된 모델의 성능을 평가해보도록 하겠습니다.
평가(Evaluating)는 모델이 예측을 얼마나 효과적으로 수행하는지 결정하는 것을 의미합니다. 붓꽃 분류 모델의 유효성을 결정하기 위해, 꽃잎과 꽃받침 데이터를 통과시키고 어떠한 품종을 예측하는지 확인합니다. 그 후 실제 품종과 비교합니다.
예를 들어, 절반의 데이터를 올바르게 예측한 모델의 정확도는 0.5입니다. 그림 4는 조금 더 효과적인 모델입니다. 5개의 예측 중 4개를 올바르게 예측하여 80% 정확도를 냅니다.
| 샘플 피쳐 | 레이블 | 모델 예측 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
|
그림 4. 80% 정확도 붓꽃 분류기. | |||||
5.1 테스트 데이터 세트 설정
모델을 평가하는 것은 모델을 학습하는 것과 유사합니다. 가장 큰 차이는 학습 데이터가 아닌 테스트 데이터셋을 사용한다는 것입니다. 공정하게 모델의 유효성을 평가하기 위해, 모델을 평가하기 위한 샘플은 반드시 학습 데이터와 달라야합니다.
테스트 데이터셋을 설정하는 것은 학습 데이터셋을 설정하는 것과 유사합니다. CSV 파일을 다운로드합니다.
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
5.2 테스트 데이터 세트를 사용한 모델 평가
학습 단계와는 다르게 모델은 테스트 데이터에 대해서 오직 한 번의 에포크를 진행합니다. 다음의 코드 셀은 테스트 셋에 있는 샘플에 대해 실행하고 실제 레이블과 비교합니다. 이는 전체 테스트 데이터셋에 대한 정확도를 측정하는데 사용됩니다.
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
logits = model(x)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("테스트 세트 정확도: {:.3%}".format(test_accuracy.result()))
마지막 배치에서 모델이 올바르게 예측한 것을 확인할 수 있습니다.
tf.stack([y,prediction],axis=1)
6. 학습된 모델로 예측하기
이제 붓꽃을 분류하기 위해 완벽하지는 않지만 어느 정도 검증된 모델을 가지고 있습니다. 학습된 모델을 사용하여 레이블 되지 않은 데이터를 예측해봅시다.
실제로 레이블 되지 않은 샘플들은 여러 소스(앱, CSV 파일, 직접 제공 등)로 제공됩니다. 지금은 레이블을 예측하기 위해 수동으로 3개의 레이블 되지 않은 샘플을 제공하겠습니다. 레이블은 다음과 같은 붓꽃 이름으로 매핑되어있습니다.
0: Iris setosa1: Iris versicolor2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
predictions = model(predict_dataset)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("샘플 {} 예측: {} ({:4.1f}%)".format(i, name, 100*p))
Copyright 2018 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.